




It is a well-known fact that Python is one of the most versatile programming languages out there, providing refuge for those who seek a general purpose language as compared to HTML, CSS or JS. But how does it achieve such a feat, and what are the inner workings behind Guido Van Rossum's masterpiece?
Compilers vs. Interpreters
- A compiler is a program that translates statements written in a high-level language into a separate machine language program, allowing you to execute said program whenever you desire.
- An interpreter uses the concept of REPL (Read, Evaluate, Print, and Loop), simultaneously translating and executing the statements written in a high-level language.
Python makes use of both, allowing for more versatility than the languages in the past - you can use either depending on what task you are trying to perform.
Efficiency Through Bytecode
The Python compiler uses a feature known as bytecode conversion, which makes way for more efficiency. When a program is done compiling, the Python compiler translates the statements into bytecode and saves it into a .pyc file (Pycache). Later, when the user wants to execute the file, the PVM (Python Virtual Machine, the interpreter) converts the bytecode into low-level machine language for direct execution on the hardware, meaning that if the .py and the .pyc files are the same (if no edits were made), it doesn't have to recompile.
Platform Independency
Python is platform independent, meaning that a program can be written once and executed on any device, given that the appropriate Python version is installed. This allows for responsiveness (consistency in appearance), something that languages such as C++ have not achieved.
This is achieved through having an interpreter built specifically for each platform (like Java uses a Java Virtual Machine (JVM) built for that platform). This StackOverflow thread pretty much sums up this idea.
Garbage Collection
Memory modification, allocation and more was usually manual in older languages. When you have unused variables, they would have to be manually cleaned from the memory. Python uses Garbage Collection to automate this process for you, employing two main methods (there are four, view them here):
- Tracing: Done by tracing which objects are reachable and not by looking through a chain of references. If an object is not reachable, it is considered as garbage.
- Reference Counting: Each object has a count of the number of references to it, and an object with a reference count of zero is considered as garbage. If a reference is added, the count increases, and if taken away, the count decreases.
Dynamic Typing
As compared to Java (which uses static typing), Python uses dynamic typing, which allows for simplicity and smaller code size - it does this through not requiring the user to declare variables before they are used. This may not necessarily be a good thing however, but Python is implemented especially for individual users that don't have a large codebase, meaning that productivity is always maximized. Also, if you want to have a large codebase, new PEPs and combining Python and Mypy (a library that allows optional static typing) support type checking, allowing for maximized productivity in large codebases.
Below is a chart showing the relation between productivity and codebase size, as mentioned in the previous statements:
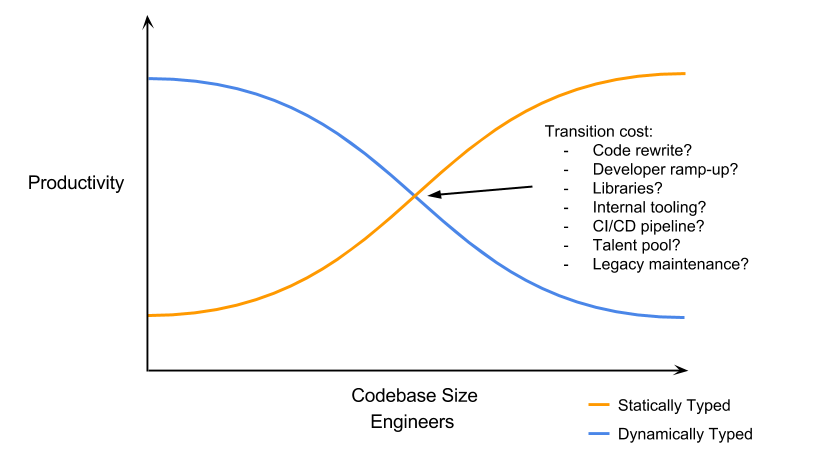 Source:
Source: